

Entanglement Overview#
Entanglement is a fully version-controlled graph analytics tool built for, among other uses, encoding use cases and answers to complex data fusion questions as a traversable knowledge graph. Many of the nodes within the graph hold references to external data and APIs, making the experience of exploring the graph go beyond simple graph analytics.
Entanglement itself is built atop a scalable, cloud-native graph database capable of scaling to millions or even billions of nodes. Currently, Entanglement supports basic graph queries such as retrieving nodes based on a free text search query or looking them up based on their ID. More specific queries will be supported in the future, but most nodes should be found through the search functionality. Once a node is returned, you can traverse the graph from there by expanding a node to find its nearest neighbors. Typically, when querying the graph, you search with a few keywords to limit the results.
Projects#
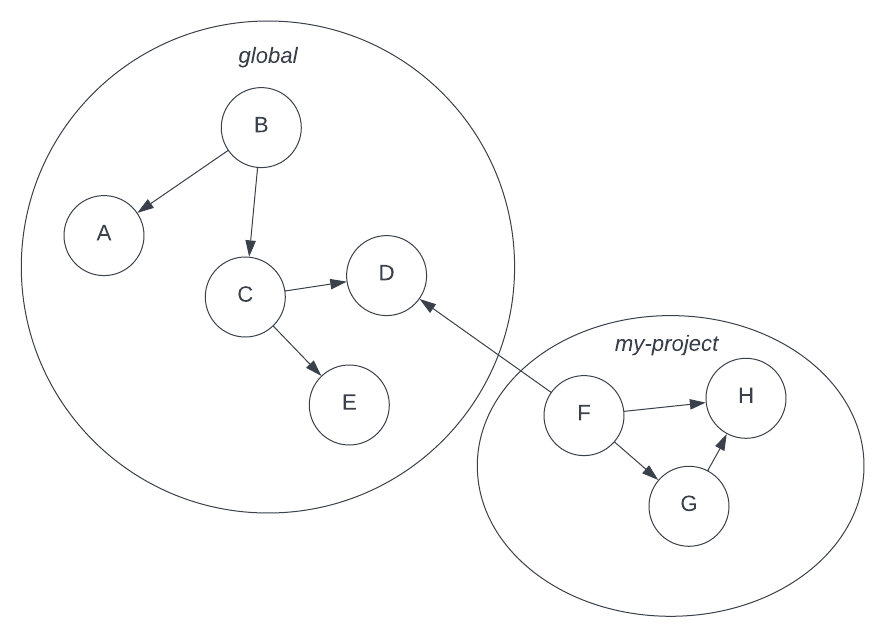
Everything in Entanglement is in one large graph. This includes all previous versions of nodes and connections. This large
graph is walled off into subgraphs, each of which we we call a Project. By default,
every User has read access to a Project called “global” and is initialized as the
default active Project. A user may create a new
Project by either instantiating the class directly with a name and alias as minimum
and calling create() on that, or by using the built-in helper function
create_project(). A user has both read and write access to any Projects they
create and can share read or write access to them them with other users.
Example:
>>> import geodesic
>>> project = geodesic.Project(name="my-test-project", alias="Test", description="a Geodesic project")
>>> project
{'name': 'my-test-project', 'alias': 'Test', 'description': 'a Geodesic project'}
>>> project.create()
>>> project
{'name': 'my-test-project', 'alias': 'Test', 'description': 'a Geodesic project', 'uid': '<autogenerated id>', 'owner': '<your subject>'}
>>> my_other_project = geodesic.create_project(name="my-other-project", alias="Other Project", description="other Geodesic project")
>>> my_other_project
{'name': 'my-other-project', 'alias': 'Other Project', 'description': 'other Geodesic project', 'uid': '<autogenerated id>', 'owner': '<your subject>'}
For more information on Project, please see the documentation on the account page or in the
geodesic.account.projects page.
Ontology#
Every node in the Entanglement graph is an Object. Two
Object are connected together by a
Predicate to form a Connection. A
Graph can be formed by combining a list of
Object and Connection. We will go into
more detail later about what makes an Object an
Object, for now we will focus on how we name things - the ontology.
Rather than build an overly prescriptive ontology, we chose to use an extremely flexible ontology suited to the needs of Geodesic but flexible enough to contain most, if not all, other ontologies. We expect the base ontology will be extended over time.
Classes#
All Object in Entanglement must have, at a minimum, a class. The class
defines “what” an Object is semantically. They are non-specific by design and
further specfication of an Object can be done by adding specific qualifiers
domain, category, type, and name. They go from less specific to more specific. Only name is
required, but more on those later. A full list of classes is listed below:
Dataset- a queryable/useable datasetModel- usable analytics/AI/ML modelEntity- a person, place or thing. (Think: a specific facility, a specific individual, etc)Concept- an abstract idea, not a physical entity. For example, the concept “corn” doesn’t refer to a kernel of corn, a crop of corn, a corn field, or anything physical, but merely the idea that there is something called “corn”.Observable- a physical property or attribute that can be observed. This is typically something like “heat”, “red” (as in, the color red), “crop-height”, etc.Observablesare something that can be observed by anEntityorDataset. This is something that some sensor or methodology is capable of observing.Property- an attribute that is not directly observable. This is typically the answer to some specific question. We will give a more concret example later.Event- something that happened at a time, and optionally, a place. An event can have its own location or reference anEntityLink- a link to an external resource, such as a webpage or perhaps a URI to another database.
If you find that this list of classes does not fit the nodes you are trying to add, please contact SeerAI at
contact@seerai.space and we will either provide guidance or consider adding a class to the ontology.
Qualifiers#
Despite a small list of classes, we expect nearly any ontology can “fit” into this structure. However, it is very
non-specific and requires additional information to represent the rich knowledge that other ontologies provide. For
that, we provide the qualifiers domain, category, and type. All of these are optional and default to a
wildcard (*) to represent lack of knowledge or unimportance in further categorization. These are entirely up to the
user, but future versions of Entanglement will enforce some level of consistency between them through
Natural Language Processing. The description of these qualifiers is listed below:
domain- refers to the overarching grouping that this node fits into. For example, aDatasetorEntitythat exposes or collects remote sensing data such as satellite imagery might have thedomain“remote-sensing”. AnEntityrepresenting a farm might have thedomain“agriculture”. AnEventrepresenting the occurence of a crime might have thedomain“crime” or perhaps “law-enforcement”.category- refers to how things are grouped together within adomain. For example, aDatasetwithdomain“remote-sensing” may be space-based and have thecategory“earth-observation”. AnEntityrepresenting a farm in thedomain“agriculture” might have acategory“corn” or even be left as “*”. AnEventrepresenting a crime in the domain “law-enforcement” might have acategory“violence”.type- you may see where this is going.typemostly refers to “what” specifically anObjectclass“is”. A satellite remote sensingDatasetorEntitymight have type “satellite”. A farm might have thetype“farm”, a crime might have the typecrime. If you put any qualifiers (besides requiredname),typeis a good one to specify as it disambiguates objects with relative ease.name- this is the only required qualifier. Anameis very specifically “which” thing anObjectis. For example, theDatasetwe’ve been refering to might be named “landsat-c2l2” refering to the level 2, collection 2 Landsat dataset hosted by USGS. The farm might be named “whispering-pines”, and the crime might be tagged with a specific crime id “crime-13C-00123” that we can use as thename(Entanglement assigns a uniqueuidto everything)
These qualifiers are important, as the combination of them uniquely identifies an
Object . In fact, the basic string representation of an object in Python is:
"<class>:<domain>:<category>:<type>:<name>" and is used by the underyling
Graph as well as the Entanglement back end to uniquely identify an object within
a Project . You’ll also note that all examples are lowercase, hyphen (-) delimited.
Because these qualifies can be used in a query, we enforce that they are all lowercase alphanumeric. The only allowed
special character a hyphen (-). No spaces. You can validate using the following regular
expression: r"^(?:[a-z]+[a-z\d-]*|\*)$" (qualifier_re). names follow
this as well, except they cannot be *.
Traits/Predicates#
A Predicate refers to a named edge between two Objects. Predicates
concisely desribe a relationship between objects with one or more all-lowercase words combined with a hyphen (-).
Similar to Objects, a Predicate may have the same qualifiers as well.
Predicates are grouped into Traits, which define what an object can do. More on that later. Some examples of
Predicates are can-observe, correlates-with, owns, supplies, etc. They should be concise and
clearly define what the relationship is.
There are two main schools of thought for organizing node classes when defining an ontology - Composition vs
Inheritance. With inheritance, one defines a hierarchy of what an Object “is”. Composition defines what traits
an Object “has”.
Inheritance Examples:
a Police Officer is a Person which is an Entity
a Hurricane is a Servere Weather Event which is an Event
a Dog is a Canine which is a type of Animal which is an Entity
Already you can see how an inheritance-based ontology gets quickly hard to manage. Especially because an Object
could be many different things. That’s a trap you run into with deep inheritance-based ontologies, and it makes it
very challenging to absorb multiple ontologies within.
We take a different approach. The only inheritance we have is that everything is an Object. We add Traits to the
small list of Object classes. A Trait is a modifier to an Object that endows it with certain
Predicate connections.
Objects#
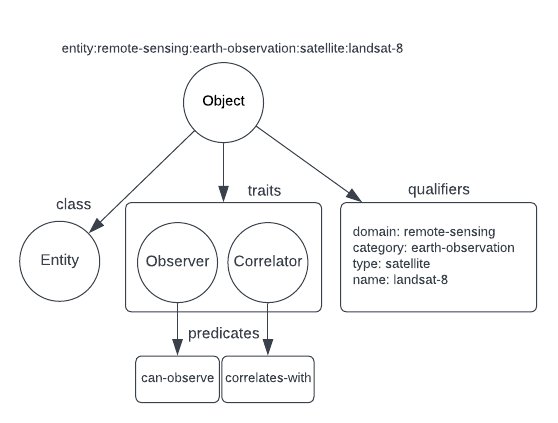
A full Object hierarchy is shown above. Don’t be alarmed if it looks complicated. The Python API makes working with
Objects fairly simple and future user interfaces will dramatically simplify how you can interact with the graph.
In addition to all of this, an Object is allowed several other top level attributes:
description- a free text description of the object. This is indexed for search, so it’s a great place to put any keywords that enable discovery of this objectgeometry- a geometry field for thisObject. This indexes thisObjectfor queries such as spatial intersections. One small deficiency in our backend that will be resolved at a future date: only points and polygons will be indexed for search. All geometries can be stored.item- a field that stores arbitrary JSON, so feel free to put anything (except secrets!) here up to 1 MB in size. This field is used frequently to store extra metadata about anObject.
For Events, we can have additional fields:
datetime- a single time instant (for example the time the event occurred)start_datetime- a time to represent the start of anEventor the start of a range if the actualEventtime is uncertainend_datetime- a time to represent the end of anEventor the end of a range if the actualEventtime is uncertain.
Connections#
A Connection is a triple composed of a subject a predicate and an
object. This is not to be confused with an RDF
triple as each component can contain rich metadata, including edge attributes that are stored on a Predicate.
Connections are just as important as Objects, since they actually supply a huge amount of information. If we had
no Connections we could think of each Object as a record in a database; they are valuable on their own, but
nothing special. The value comes from their connections. Consider the following: If I have 2 Objects, I have two
pieces of information. If I draw a connection between them, I have 3. If I have 3 Objects, I can draw a connection
between each pair, giving up to a total of 6 pieces of information. For 4 Objects, I could have 10 pieces of
information, and so on. The number of possible Connections grows quadratically with the the number of nodes. Storing
and maintaining these connections means our available information grows MUCH faster than if we just focused on the
Objects alone.
Version Control#
Entanglement is fully version-controlled. Every time you add, modify, or delete an Object or Connection, that
change is saved. When you execute a query against Entanglement, the default behavior is to query the latest state of
the graph. You can also optionally supply a datetime to an Objects query to retrieve the objects as the were at that
point in time. The same is true for Connections.
Note
While you CAN use data versioning to keep a time series of values for a particular node, it’s not recommended to do so. We recommend storing data that changes infrequently in Entanglement. For example, I might have a node representing “corn price”, but we would not recommend updating that node with the daily value with version control, and alternatively suggest making the corn price node point to an external dataset intended for dynamic data. Use your best judgement on this.
Basic Operations#
Now that we’ve covered some of the design principles behind Entanglement
Enough about the theory and design, let’s get practical. In the Entanglement examples </source/notebooks/entanglement_01.ipynb>
you will find a Jupyter notebook that walks through the basic operations of Entanglement. This includes creating a
Project, adding Objects and Connections to the graph, and querying the graph
for information.